1.线程同步概念
假设有4个线程A、B、C、D,当前一个线程A对内存中的
共享资源进行访问的时候,其他线程B, C, D都不可以对这块内存进行操作,直到线程A对这块内存访问完毕为止,B,C,D中的一个才能访问这块内存,剩余的两个需要继续阻塞等待,以此类推,直至所有的线程都对这块内存操作完毕。 线程对内存的这种访问方式就称之为线程同步,通过对概念的介绍,我们可以了解到所谓的同步并不是多个线程同时对内存进行访问,而是按照先后顺序依次进行的。1.1 为什么要同步
在研究线程同步之前,先来看一个两个线程交替数数(每个线程数50个数,交替数到100)的例子:
#include <stdio.h> #include <unistd.h> #include <stdlib.h> #include <sys/types.h> #include <sys/stat.h> #include <string.h> #include <pthread.h> #define MAX 50 // 全局变量 int number; // 线程处理函数 void* funcA_num(void* arg) { for(int i=0; i<MAX; ++i) { int cur = number; cur++; usleep(10); number = cur; printf("Thread A, id = %lu, number = %d\n", pthread_self(), number); } return NULL; } void* funcB_num(void* arg) { for(int i=0; i<MAX; ++i) { int cur = number; cur++; number = cur; printf("Thread B, id = %lu, number = %d\n", pthread_self(), number); usleep(5); } return NULL; } int main(int argc, const char* argv[]) { pthread_t p1, p2; // 创建两个子线程 pthread_create(&p1, NULL, funcA_num, NULL); pthread_create(&p2, NULL, funcB_num, NULL); // 阻塞,资源回收 pthread_join(p1, NULL); pthread_join(p2, NULL); return 0; }
编译并执行上面的测试程序,得到如下结果:
$ ./a.out Thread B, id = 140504473724672, number = 1 Thread B, id = 140504473724672, number = 2 Thread A, id = 140504482117376, number = 2 Thread B, id = 140504473724672, number = 3 Thread A, id = 140504482117376, number = 4 Thread B, id = 140504473724672, number = 5 Thread A, id = 140504482117376, number = 6 Thread B, id = 140504473724672, number = 7 Thread B, id = 140504473724672, number = 8 Thread A, id = 140504482117376, number = 7 Thread B, id = 140504473724672, number = 8 Thread B, id = 140504473724672, number = 9 Thread A, id = 140504482117376, number = 8 Thread B, id = 140504473724672, number = 9 Thread A, id = 140504482117376, number = 9 Thread B, id = 140504473724672, number = 10 Thread B, id = 140504473724672, number = 11 Thread A, id = 140504482117376, number = 10 Thread B, id = 140504473724672, number = 11 Thread A, id = 140504482117376, number = 11 Thread B, id = 140504473724672, number = 12 Thread A, id = 140504482117376, number = 13 Thread B, id = 140504473724672, number = 14 Thread A, id = 140504482117376, number = 15 Thread B, id = 140504473724672, number = 16 Thread B, id = 140504473724672, number = 17 Thread B, id = 140504473724672, number = 18 Thread B, id = 140504473724672, number = 19 Thread A, id = 140504482117376, number = 17 Thread B, id = 140504473724672, number = 18 Thread B, id = 140504473724672, number = 19 Thread A, id = 140504482117376, number = 19 Thread B, id = 140504473724672, number = 20 Thread A, id = 140504482117376, number = 20 Thread B, id = 140504473724672, number = 21 Thread A, id = 140504482117376, number = 21 Thread B, id = 140504473724672, number = 22 Thread A, id = 140504482117376, number = 22 Thread B, id = 140504473724672, number = 23 Thread A, id = 140504482117376, number = 23 Thread B, id = 140504473724672, number = 24 Thread A, id = 140504482117376, number = 24 Thread B, id = 140504473724672, number = 25 Thread A, id = 140504482117376, number = 25 Thread B, id = 140504473724672, number = 26 Thread A, id = 140504482117376, number = 26 Thread B, id = 140504473724672, number = 27 Thread A, id = 140504482117376, number = 27 Thread B, id = 140504473724672, number = 28 Thread A, id = 140504482117376, number = 28 Thread B, id = 140504473724672, number = 29 Thread A, id = 140504482117376, number = 29 Thread B, id = 140504473724672, number = 30 Thread A, id = 140504482117376, number = 30 Thread B, id = 140504473724672, number = 31 Thread A, id = 140504482117376, number = 31 Thread B, id = 140504473724672, number = 32 Thread A, id = 140504482117376, number = 32 Thread B, id = 140504473724672, number = 33 Thread A, id = 140504482117376, number = 33 Thread B, id = 140504473724672, number = 34 Thread A, id = 140504482117376, number = 34 Thread B, id = 140504473724672, number = 35 Thread A, id = 140504482117376, number = 35 Thread B, id = 140504473724672, number = 36 Thread A, id = 140504482117376, number = 36 Thread B, id = 140504473724672, number = 37 Thread A, id = 140504482117376, number = 37 Thread B, id = 140504473724672, number = 38 Thread A, id = 140504482117376, number = 38 Thread B, id = 140504473724672, number = 39 Thread A, id = 140504482117376, number = 39 Thread A, id = 140504482117376, number = 40 Thread B, id = 140504473724672, number = 41 Thread B, id = 140504473724672, number = 42 Thread A, id = 140504482117376, number = 42 Thread A, id = 140504482117376, number = 43 Thread B, id = 140504473724672, number = 44 Thread B, id = 140504473724672, number = 45 Thread A, id = 140504482117376, number = 45 Thread B, id = 140504473724672, number = 46 Thread A, id = 140504482117376, number = 46 Thread B, id = 140504473724672, number = 47 Thread A, id = 140504482117376, number = 47 Thread B, id = 140504473724672, number = 48 Thread A, id = 140504482117376, number = 48 Thread B, id = 140504473724672, number = 49 Thread A, id = 140504482117376, number = 50 Thread B, id = 140504473724672, number = 51 Thread A, id = 140504482117376, number = 51 Thread B, id = 140504473724672, number = 52 Thread A, id = 140504482117376, number = 53 Thread A, id = 140504482117376, number = 54 Thread A, id = 140504482117376, number = 55 Thread A, id = 140504482117376, number = 56 Thread A, id = 140504482117376, number = 57 Thread A, id = 140504482117376, number = 58 Thread A, id = 140504482117376, number = 59 Thread A, id = 140504482117376, number = 60 Thread A, id = 140504482117376, number = 61 robin@OS:~/abc/b$
通过对上面例子的测试,可以看出虽然每个线程内部循环了50次每次数一个数,但是最终没有数到100,通过输出的结果可以看到,有些数字被重复数了多次,其原因就是没有对线程进行同步处理,造成了数据的混乱。
两个线程在数数的时候需要分时复用CPU时间片,并且测试程序中调用了
sleep()导致线程的CPU时间片没用完就被迫挂起了,这样就能让CPU的上下文切换(保存当前状态, 下一次继续运行的时候需要加载保存的状态)更加频繁,更容易再现数据混乱的这个现象。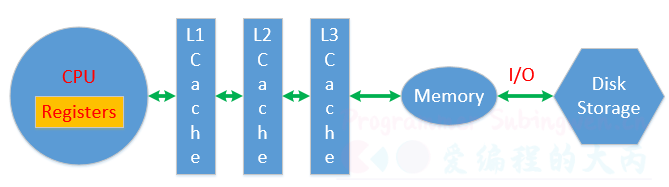
CPU对应寄存器、一级缓存、二级缓存、三级缓存是独占的,用于存储处理的数据和线程的状态信息,数据被CPU处理完成需要再次被写入到物理内存中,物理内存数据也可以通过文件IO操作写入到磁盘中。
在测试程序中两个线程共用全局变量
number当线程变成运行态之后开始数数,从物理内存加载数据,让后将数据放到CPU进行运算,最后将结果更新到物理内存中。如果数数的两个线程都可以顺利完成这个流程,那么得到的结果肯定是正确的。如果线程A执行这个过程期间就失去了CPU时间片,线程A被挂起了最新的数据没能更新到物理内存。线程B变成运行态之后从物理内存读数据,很显然它没有拿到最新数据,只能基于旧的数据往后数,然后失去CPU时间片挂起。线程A得到CPU时间片变成运行态,第一件事儿就是将上次没更新到内存的数据更新到内存,但是这样会导致线程B已经更新到内存的数据被覆盖,活儿白干了,最终导致有些数据会被重复数很多次。
1.2 同步方式
对于多个线程访问共享资源出现数据混乱的问题,需要进行线程同步。常用的线程同步方式有四种:互斥锁、读写锁、条件变量、信号量。所谓的共享资源就是多个线程共同访问的变量,这些变量通常为全局数据区变量或者堆区变量,这些变量对应的共享资源也被称之为临界资源。
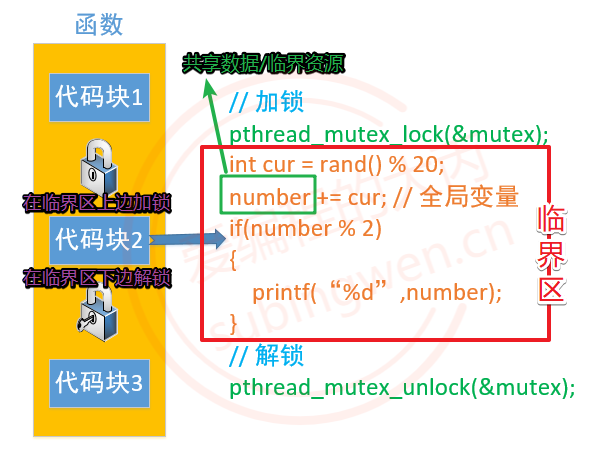
找到临界资源之后,再找和临界资源相关的上下文代码,这样就得到了一个代码块,这个代码块可以称之为临界区。确定好临界区(临界区越小越好)之后,就可以进行线程同步了,线程同步的大致处理思路是这样的:
- 在临界区代码的上边,添加加锁函数,对临界区加锁。
- 哪个线程调用这句代码,就会把这把锁锁上,其他线程就只能阻塞在锁上了。
- 在临界区代码的下边,添加解锁函数,对临界区解锁。
- 出临界区的线程会将锁定的那把锁打开,其他抢到锁的线程就可以进入到临界区了。
- 通过锁机制能保证临界区代码最多只能同时有一个线程访问,这样并行访问就变为串行访问了。
2.互斥锁
2.1 互斥锁函数
互斥锁是线程同步最常用的一种方式,通过互斥锁可以锁定一个代码块, 被锁定的这个代码块, 所有的线程只能顺序执行(不能并行处理),这样多线程访问共享资源数据混乱的问题就可以被解决了,需要付出的代价就是执行效率的降低,因为默认临界区多个线程是可以并行处理的,现在只能串行处理。
在Linux中互斥锁的类型为
pthread_mutex_t,创建一个这种类型的变量就得到了一把互斥锁:pthread_mutex_t mutex;
在创建的锁对象中保存了当前这把锁的状态信息:锁定还是打开,如果是锁定状态还记录了给这把锁加锁的线程信息(线程ID)。一个互斥锁变量只能被一个线程锁定,被锁定之后其他线程再对互斥锁变量加锁就会被阻塞,直到这把互斥锁被解锁,被阻塞的线程才能被解除阻塞。一般情况下,每一个共享资源对应一个把互斥锁,锁的个数和线程的个数无关。
Linux 提供的互斥锁操作函数如下,如果函数调用成功会返回0,调用失败会返回相应的错误号:
// 初始化互斥锁 // restrict: 是一个关键字, 用来修饰指针, 只有这个关键字修饰的指针可以访问指向的内存地址, 其他指针是不行的 int pthread_mutex_init(pthread_mutex_t *restrict mutex, const pthread_mutexattr_t *restrict attr); // 释放互斥锁资源 int pthread_mutex_destroy(pthread_mutex_t *mutex);
- 参数:
mutex: 互斥锁变量的地址attr: 互斥锁的属性, 一般使用默认属性即可, 这个参数指定为NULL
// 修改互斥锁的状态, 将其设定为锁定状态, 这个状态被写入到参数 mutex 中 int pthread_mutex_lock(pthread_mutex_t *mutex);
这个函数被调用, 首先会判断参数
mutex 互斥锁中的状态是不是锁定状态:- 没有被锁定, 是打开的, 这个线程可以加锁成功, 这个锁中会记录是哪个线程加锁成功了
- 如果被锁定了, 其他线程加锁就失败了, 这些线程都会阻塞在这把锁上
- 当这把锁被解开之后, 这些阻塞在锁上的线程就解除阻塞了,并且这些线程是通过竞争的方式对这把锁加锁,没抢到锁的线程继续阻塞
// 尝试加锁 int pthread_mutex_trylock(pthread_mutex_t *mutex);
调用这个函数对互斥锁变量加锁还是有两种情况:
- 如果这把锁没有被锁定是打开的,线程加锁成功
- 如果锁变量被锁住了,调用这个函数加锁的线程,不会被阻塞,加锁失败直接返回错误号
// 对互斥锁解锁 int pthread_mutex_unlock(pthread_mutex_t *mutex);
不是所有的线程都可以对互斥锁解锁,哪个线程加的锁, 哪个线程才能解锁成功。
2.2 互斥锁使用
我们可以将上面多线程交替数数的例子修改一下,使用互斥锁进行线程同步。两个线程一共操作了同一个全局变量,因此需要添加一互斥锁,来控制这两个线程。
#include <stdio.h> #include <unistd.h> #include <stdlib.h> #include <sys/types.h> #include <sys/stat.h> #include <string.h> #include <pthread.h> #define MAX 100 // 全局变量 int number; // 创建一把互斥锁 // 全局变量, 多个线程共享 pthread_mutex_t mutex; // 线程处理函数 void* funcA_num(void* arg) { for(int i=0; i<MAX; ++i) { // 如果线程A加锁成功, 不阻塞 // 如果B加锁成功, 线程A阻塞 pthread_mutex_lock(&mutex); int cur = number; cur++; usleep(10); number = cur; pthread_mutex_unlock(&mutex); printf("Thread A, id = %lu, number = %d\n", pthread_self(), number); } return NULL; } void* funcB_num(void* arg) { for(int i=0; i<MAX; ++i) { // a加锁成功, b线程访问这把锁的时候是锁定的 // 线程B先阻塞, a线程解锁之后阻塞解除 // 线程B加锁成功了 pthread_mutex_lock(&mutex); int cur = number; cur++; number = cur; pthread_mutex_unlock(&mutex); printf("Thread B, id = %lu, number = %d\n", pthread_self(), number); usleep(5); } return NULL; } int main(int argc, const char* argv[]) { pthread_t p1, p2; // 初始化互斥锁 pthread_mutex_init(&mutex, NULL); // 创建两个子线程 pthread_create(&p1, NULL, funcA_num, NULL); pthread_create(&p2, NULL, funcB_num, NULL); // 阻塞,资源回收 pthread_join(p1, NULL); pthread_join(p2, NULL); // 销毁互斥锁 // 线程销毁之后, 再去释放互斥锁 pthread_mutex_destroy(&mutex); return 0; }
3.死锁
当多个线程访问共享资源, 需要加锁, 如果锁使用不当, 就会造成死锁这种现象。如果线程死锁造成的后果是:所有的线程都被阻塞,并且线程的阻塞是无法解开的(因为可以解锁的线程也被阻塞了)。
造成死锁的场景有如下几种:
(1)加锁之后忘记解锁
// 场景1 void func() { for(int i=0; i<6; ++i) { // 当前线程A加锁成功, 当前循环完毕没有解锁, 在下一轮循环的时候自己被阻塞了 // 其余的线程也被阻塞 pthread_mutex_lock(&mutex); .... ..... // 忘记解锁 } } // 场景2 void func() { for(int i=0; i<6; ++i) { // 当前线程A加锁成功 // 其余的线程被阻塞 pthread_mutex_lock(&mutex); .... ..... if(xxx) { // 函数退出, 没有解锁(解锁函数无法被执行了) return ; } pthread_mutex_lock(&mutex); } }
(2)重复加锁, 造成死锁
void func() { for(int i=0; i<6; ++i) { // 当前线程A加锁成功 // 其余的线程阻塞 pthread_mutex_lock(&mutex); // 锁被锁住了, A线程阻塞 pthread_mutex_lock(&mutex); .... ..... pthread_mutex_unlock(&mutex); } } // 隐藏的比较深的情况 void funcA() { for(int i=0; i<6; ++i) { // 当前线程A加锁成功 // 其余的线程阻塞 pthread_mutex_lock(&mutex); .... ..... pthread_mutex_unlock(&mutex); } } void funcB() { for(int i=0; i<6; ++i) { // 当前线程A加锁成功 // 其余的线程阻塞 pthread_mutex_lock(&mutex); funcA(); // 重复加锁 .... ..... pthread_mutex_unlock(&mutex); } }
(3)随意加锁
在程序中有多个共享资源, 因此有很多把锁,随意加锁,导致相互被阻塞
场景描述:
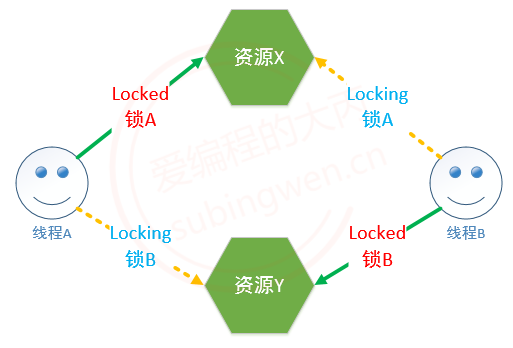
1. 有两个共享资源:X, Y,X对应锁A, Y对应锁B
- 线程A访问资源X, 加锁A
- 线程B访问资源Y, 加锁B
2. 线程A要访问资源Y, 线程B要访问资源X,因为资源X和Y已经被对应的锁锁住了,因此这个两个线程被阻塞
- 线程A被锁B阻塞了, 无法打开A锁
- 线程B被锁A阻塞了, 无法打开B锁
在使用多线程编程的时候,如何避免死锁呢?
- 避免多次锁定, 多检查
- 对共享资源访问完毕之后, 一定要解锁,或者在加锁的使用
trylock - 如果程序中有多把锁, 可以控制对锁的访问顺序(顺序访问共享资源,但在有些情况下是做不到的),另外也可以在对其他互斥锁做加锁操作之前,先释放当前线程拥有的互斥锁。
- 项目程序中可以引入一些专门用于死锁检测的模块
4.读写锁
4.1 读写锁函数
读写锁是互斥锁的升级版, 在做读操作的时候可以提高程序的执行效率,如果所有的线程都是做读操作, 那么读是并行的,但是使用互斥锁,读操作也是串行的。
读写锁是一把锁,锁的类型为
pthread_rwlock_t,有了类型之后就可以创建一把互斥锁了:pthread_rwlock_t rwlock;
之所以称其为读写锁,是因为这把锁既可以锁定读操作,也可以锁定写操作。为了方便理解,可以大致认为在这把锁中记录了这些信息:
- 锁的状态: 锁定/打开
- 锁定的是什么操作: 读操作/写操作,使用读写锁锁定了读操作,需要先解锁才能去锁定写操作,反之亦然。
- 哪个线程将这把锁锁上了
读写锁的使用方式也互斥锁的使用方式是完全相同的:找共享资源, 确定临界区,在临界区的开始位置加锁(读锁/写锁),临界区的结束位置解锁。
因为通过一把读写锁可以锁定读或者写操作,下面介绍一下关于读写锁的特点:
- 使用读写锁的读锁锁定了临界区,线程对临界区的访问是并行的,读锁是共享的。
- 使用读写锁的写锁锁定了临界区,线程对临界区的访问是串行的,写锁是独占的。
- 使用读写锁分别对两个临界区加了读锁和写锁,两个线程要同时访问者两个临界区,访问写锁临界区的线程继续运行,访问读锁临界区的线程阻塞,因为写锁比读锁的优先级高。
如果说程序中所有的线程都对共享资源做写操作,使用读写锁没有优势,和互斥锁是一样的,如果说程序中所有的线程都对共享资源有写也有读操作,并且对共享资源读的操作越多,读写锁更有优势。
Linux提供的读写锁操作函数原型如下,如果函数调用成功返回0,失败返回对应的错误号:
#include <pthread.h> pthread_rwlock_t rwlock; // 初始化读写锁 int pthread_rwlock_init(pthread_rwlock_t *restrict rwlock, const pthread_rwlockattr_t *restrict attr); // 释放读写锁占用的系统资源 int pthread_rwlock_destroy(pthread_rwlock_t *rwlock);
- 参数:
rwlock: 读写锁的地址,传出参数attr: 读写锁属性,一般使用默认属性,指定为NULL
// 在程序中对读写锁加读锁, 锁定的是读操作 int pthread_rwlock_rdlock(pthread_rwlock_t *rwlock);
调用这个函数,如果读写锁是打开的,那么加锁成功;如果读写锁已经锁定了读操作,调用这个函数依然可以加锁成功,因为读锁是共享的;如果读写锁已经锁定了写操作,调用这个函数的线程会被阻塞。
// 这个函数可以有效的避免死锁 // 如果加读锁失败, 不会阻塞当前线程, 直接返回错误号 int pthread_rwlock_tryrdlock(pthread_rwlock_t *rwlock);
调用这个函数,如果读写锁是打开的,那么加锁成功;如果读写锁已经锁定了读操作,调用这个函数依然可以加锁成功,因为读锁是共享的;如果读写锁已经锁定了写操作,调用这个函数加锁失败,对应的线程不会被阻塞,可以在程序中对函数返回值进行判断,添加加锁失败之后的处理动作。
// 在程序中对读写锁加写锁, 锁定的是写操作 int pthread_rwlock_wrlock(pthread_rwlock_t *rwlock);
调用这个函数,如果读写锁是打开的,那么加锁成功;如果读写锁已经锁定了读操作或者锁定了写操作,调用这个函数的线程会被阻塞。
// 这个函数可以有效的避免死锁 // 如果加写锁失败, 不会阻塞当前线程, 直接返回错误号 int pthread_rwlock_trywrlock(pthread_rwlock_t *rwlock);
调用这个函数,如果读写锁是打开的,那么加锁成功;如果读写锁已经锁定了读操作或者锁定了写操作,调用这个函数加锁失败,但是线程不会阻塞,可以在程序中对函数返回值进行判断,添加加锁失败之后的处理动作。
// 解锁, 不管锁定了读还是写都可用解锁 int pthread_rwlock_unlock(pthread_rwlock_t *rwlock);
4.2 读写锁使用
题目要求:8个线程操作同一个全局变量,3个线程不定时写同一全局资源,5个线程不定时读同一全局资源。
#include <stdio.h> #include <stdlib.h> #include <unistd.h> #include <string.h> #include <pthread.h> // 全局变量 int number = 0; // 定义读写锁 pthread_rwlock_t rwlock; // 写的线程的处理函数 void* writeNum(void* arg) { while(1) { pthread_rwlock_wrlock(&rwlock); int cur = number; cur ++; number = cur; printf("++写操作完毕, number : %d, tid = %ld\n", number, pthread_self()); pthread_rwlock_unlock(&rwlock); // 添加sleep目的是要看到多个线程交替工作 usleep(rand() % 100); } return NULL; } // 读线程的处理函数 // 多个线程可以如果处理动作相同, 可以使用相同的处理函数 // 每个线程中的栈资源是独享 void* readNum(void* arg) { while(1) { pthread_rwlock_rdlock(&rwlock); printf("--全局变量number = %d, tid = %ld\n", number, pthread_self()); pthread_rwlock_unlock(&rwlock); usleep(rand() % 100); } return NULL; } int main() { // 初始化读写锁 pthread_rwlock_init(&rwlock, NULL); // 3个写线程, 5个读的线程 pthread_t wtid[3]; pthread_t rtid[5]; for(int i=0; i<3; ++i) { pthread_create(&wtid[i], NULL, writeNum, NULL); } for(int i=0; i<5; ++i) { pthread_create(&rtid[i], NULL, readNum, NULL); } // 释放资源 for(int i=0; i<3; ++i) { pthread_join(wtid[i], NULL); } for(int i=0; i<5; ++i) { pthread_join(rtid[i], NULL); } // 销毁读写锁 pthread_rwlock_destroy(&rwlock); return 0; }
5.条件变量
5.1 条件变量函数
严格意义上来说,条件变量的主要作用不是处理线程同步, 而是进行线程的阻塞。如果在多线程程序中只使用条件变量无法实现线程的同步, 必须要配合互斥锁来使用。虽然条件变量和互斥锁都能阻塞线程,但是二者的效果是不一样的,二者的区别如下:
- 假设有A-Z 26个线程,这26个线程共同访问同一把互斥锁,如果线程A加锁成功,那么其余B-Z线程访问互斥锁都阻塞,所有的线程只能顺序访问临界区
- 条件变量只有在满足指定条件下才会阻塞线程,如果条件不满足,多个线程可以同时进入临界区,同时读写临界资源,这种情况下还是会出现共享资源中数据的混乱。
一般情况下条件变量用于处理生产者和消费者模型,并且和互斥锁配合使用。条件变量类型对应的类型为
pthread_cond_t,这样就可以定义一个条件变量类型的变量了:pthread_cond_t cond;
被条件变量阻塞的线程的线程信息会被记录到这个变量中,以便在解除阻塞的时候使用。
条件变量操作函数函数原型如下:
#include <pthread.h> pthread_cond_t cond; // 初始化 int pthread_cond_init(pthread_cond_t *restrict cond, const pthread_condattr_t *restrict attr); // 销毁释放资源 int pthread_cond_destroy(pthread_cond_t *cond);
- 参数:
cond: 条件变量的地址attr: 条件变量属性, 一般使用默认属性, 指定为NULL
// 线程阻塞函数, 哪个线程调用这个函数, 哪个线程就会被阻塞 int pthread_cond_wait(pthread_cond_t *restrict cond, pthread_mutex_t *restrict mutex);
通过函数原型可以看出,该函数在阻塞线程的时候,需要一个互斥锁参数,这个互斥锁主要功能是进行线程同步,让线程顺序进入临界区,避免出现数共享资源的数据混乱。该函数会对这个互斥锁做以下几件事情:
- 在阻塞线程时候,如果线程已经对互斥锁
mutex上锁,那么会将这把锁打开,这样做是为了避免死锁 - 当线程解除阻塞的时候,函数内部会帮助这个线程再次将这个
mutex互斥锁锁上,继续向下访问临界区
// 表示的时间是从1971.1.1到某个时间点的时间, 总长度使用秒/纳秒表示 struct timespec { time_t tv_sec; /* Seconds */ long tv_nsec; /* Nanoseconds [0 .. 999999999] */ }; // 将线程阻塞一定的时间长度, 时间到达之后, 线程就解除阻塞了 int pthread_cond_timedwait(pthread_cond_t *restrict cond, pthread_mutex_t *restrict mutex, const struct timespec *restrict abstime);
这个函数的前两个参数和
pthread_cond_wait函数是一样的,第三个参数表示线程阻塞的时长,但是需要额外注意一点:struct timespec这个结构体中记录的时间是从1971.1.1到某个时间点的时间,总长度使用秒/纳秒表示。因此赋值方式相对要麻烦一点:time_t mytim = time(NULL); // 1970.1.1 0:0:0 到当前的总秒数 struct timespec tmsp; tmsp.tv_nsec = 0; tmsp.tv_sec = time(NULL) + 100; // 线程阻塞100s
// 唤醒阻塞在条件变量上的线程, 至少有一个被解除阻塞 int pthread_cond_signal(pthread_cond_t *cond); // 唤醒阻塞在条件变量上的线程, 被阻塞的线程全部解除阻塞 int pthread_cond_broadcast(pthread_cond_t *cond);
调用上面两个函数中的任意一个,都可以换线被
pthread_cond_wait或者pthread_cond_timedwait阻塞的线程,区别就在于pthread_cond_signal是唤醒至少一个被阻塞的线程(总个数不定),pthread_cond_broadcast是唤醒所有被阻塞的线程。5.2 生产者和消费者
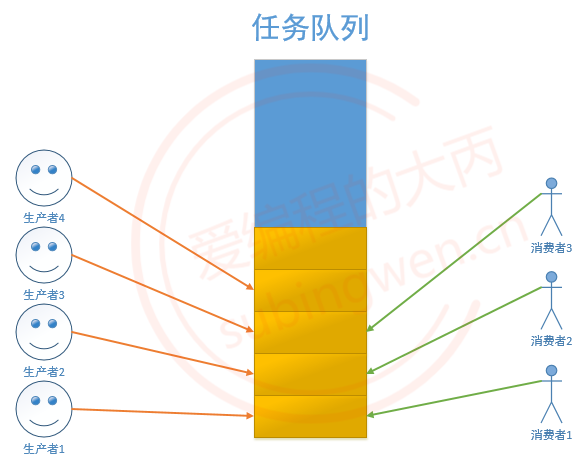
生产者和消费者模型的组成:
- 生产者线程 -> 若干个
- 生产商品或者任务放入到任务队列中
- 任务队列满了就阻塞, 不满的时候就工作
- 通过一个生产者的条件变量控制生产者线程阻塞和非阻塞
- 消费者线程 -> 若干个
- 读任务队列, 将任务或者数据取出
- 任务队列中有数据就消费,没有数据就阻塞
- 通过一个消费者的条件变量控制消费者线程阻塞和非阻塞
- 队列 -> 存储任务/数据,对应一块内存,为了读写访问可以通过一个数据结构维护这块内存
- 可以是数组、链表,也可以使用stl容器:queue / stack / list / vector
场景描述:使用条件变量实现生产者和消费者模型,生产者有5个,往链表头部添加节点,消费者也有5个,删除链表头部的节点。
#include <stdio.h> #include <stdlib.h> #include <unistd.h> #include <string.h> #include <pthread.h> // 链表的节点 struct Node { int number; struct Node* next; }; // 定义条件变量, 控制消费者线程 pthread_cond_t cond; // 互斥锁变量 pthread_mutex_t mutex; // 指向头结点的指针 struct Node * head = NULL; // 生产者的回调函数 void* producer(void* arg) { // 一直生产 while(1) { pthread_mutex_lock(&mutex); // 创建一个链表的新节点 struct Node* pnew = (struct Node*)malloc(sizeof(struct Node)); // 节点初始化 pnew->number = rand() % 1000; // 节点的连接, 添加到链表的头部, 新节点就新的头结点 pnew->next = head; // head指针前移 head = pnew; printf("+++producer, number = %d, tid = %ld\n", pnew->number, pthread_self()); pthread_mutex_unlock(&mutex); // 生产了任务, 通知消费者消费 pthread_cond_broadcast(&cond); // 生产慢一点 sleep(rand() % 3); } return NULL; } // 消费者的回调函数 void* consumer(void* arg) { while(1) { pthread_mutex_lock(&mutex); // 一直消费, 删除链表中的一个节点 // if(head == NULL) // 这样写有bug while(head == NULL) { // 任务队列, 也就是链表中已经没有节点可以消费了 // 消费者线程需要阻塞 // 线程加互斥锁成功, 但是线程阻塞在这行代码上, 锁还没解开 // 其他线程在访问这把锁的时候也会阻塞, 生产者也会阻塞 ==> 死锁 // 这函数会自动将线程拥有的锁解开 pthread_cond_wait(&cond, &mutex); // 当消费者线程解除阻塞之后, 会自动将这把锁锁上 // 这时候当前这个线程又重新拥有了这把互斥锁 } // 取出链表的头结点, 将其删除 struct Node* pnode = head; printf("--consumer: number: %d, tid = %ld\n", pnode->number, pthread_self()); head = pnode->next; free(pnode); pthread_mutex_unlock(&mutex); sleep(rand() % 3); } return NULL; } int main() { // 初始化条件变量 pthread_cond_init(&cond, NULL); pthread_mutex_init(&mutex, NULL); // 创建5个生产者, 5个消费者 pthread_t ptid[5]; pthread_t ctid[5]; for(int i=0; i<5; ++i) { pthread_create(&ptid[i], NULL, producer, NULL); } for(int i=0; i<5; ++i) { pthread_create(&ctid[i], NULL, consumer, NULL); } // 释放资源 for(int i=0; i<5; ++i) { // 阻塞等待子线程退出 pthread_join(ptid[i], NULL); } for(int i=0; i<5; ++i) { pthread_join(ctid[i], NULL); } // 销毁条件变量 pthread_cond_destroy(&cond); pthread_mutex_destroy(&mutex); return 0; }
代码分析
void* consumer(void* arg) { while(1) { pthread_mutex_lock(&mutex); // 一直消费, 删除链表中的一个节点 if(head == NULL) // 这样写有bug { pthread_cond_wait(&cond, &mutex); } // 取出链表的头结点, 将其删除 struct Node* pnode = head; printf("--consumer: number: %d, tid = %ld\n", pnode->number, pthread_self()); head = pnode->next; free(pnode); pthread_mutex_unlock(&mutex); sleep(rand() % 3); } return NULL; } /* 为什么在第7行使用if 有bug: 当任务队列为空, 所有的消费者线程都会被这个函数阻塞 pthread_cond_wait(&cond, &mutex); 也就是阻塞在代码的第9行 当生产者生产了1个节点, 调用 pthread_cond_broadcast(&cond); 唤醒了所有阻塞的线程 - 有一个消费者线程通过 pthread_cond_wait()加锁成功, 其余没有加锁成功的线程继续阻塞 - 加锁成功的线程向下运行, 并成功删除一个节点, 然后解锁 - 没有加锁成功的线程解除阻塞继续抢这把锁, 另外一个子线程加锁成功 - 但是这个线程删除链表节点的时候链表已经为空了, 后边访问这个空节点的时候就会出现段错误 解决方案: - 需要循环的对链表是否为空进行判断, 需要将if 该成 while */
6.信号量
6.1 信号量函数
信号量用在多线程多任务同步的,一个线程完成了某一个动作就通过信号量告诉别的线程,别的线程再进行某些动作。信号量不一定是锁定某一个资源,而是流程上的概念,比如:有A,B两个线程,B线程要等A线程完成某一任务以后再进行自己下面的步骤,这个任务并不一定是锁定某一资源,还可以是进行一些计算或者数据处理之类。
信号量(信号灯)与互斥锁和条件变量的主要不同在于”灯”的概念,灯亮则意味着资源可用,灯灭则意味着不可用。信号量主要阻塞线程, 不能完全保证线程安全,如果要保证线程安全, 需要信号量和互斥锁一起使用。
信号量和条件变量一样用于处理生产者和消费者模型,用于阻塞生产者线程或者消费者线程的运行。信号的类型为
sem_t对应的头文件为<semaphore.h>:#include <semaphore.h> sem_t sem;
Linux提供的信号量操作函数原型如下:
#include <semaphore.h> // 初始化信号量/信号灯 int sem_init(sem_t *sem, int pshared, unsigned int value); // 资源释放, 线程销毁之后调用这个函数即可 // 参数 sem 就是 sem_init() 的第一个参数 int sem_destroy(sem_t *sem);
- 参数:
sem:信号量变量地址pshared:- 0:线程同步
- 非0:进程同步
- value:初始化当前信号量拥有的资源数(>=0),如果资源数为0,线程就会被阻塞了。
// 参数 sem 就是 sem_init() 的第一个参数 // 函数被调用sem中的资源就会被消耗1个, 资源数-1 int sem_wait(sem_t *sem);
当线程调用这个函数,并且
sem中的资源数>0,线程不会阻塞,线程会占用sem中的一个资源,因此资源数-1,直到sem中的资源数减为0时,资源被耗尽,因此线程也就被阻塞了。// 参数 sem 就是 sem_init() 的第一个参数 // 函数被调用sem中的资源就会被消耗1个, 资源数-1 int sem_trywait(sem_t *sem);
当线程调用这个函数,并且
sem中的资源数>0,线程不会阻塞,线程会占用sem中的一个资源,因此资源数-1,直到sem中的资源数减为0时,资源被耗尽,但是线程不会被阻塞,直接返回错误号,因此可以在程序中添加判断分支,用于处理获取资源失败之后的情况。// 表示的时间是从1971.1.1到某个时间点的时间, 总长度使用秒/纳秒表示 struct timespec { time_t tv_sec; /* Seconds */ long tv_nsec; /* Nanoseconds [0 .. 999999999] */ }; // 调用该函数线程获取sem中的一个资源,当资源数为0时,线程阻塞,在阻塞abs_timeout对应的时长之后,解除阻塞。 // abs_timeout: 阻塞的时间长度, 单位是s, 是从1970.1.1开始计算的 int sem_timedwait(sem_t *sem, const struct timespec *abs_timeout);
该函数的参数
abs_timeout和pthread_cond_timedwait的最后一个参数是一样的,使用方法不再过多赘述。当线程调用这个函数,并且sem中的资源数>0,线程不会阻塞,线程会占用sem中的一个资源,因此资源数-1,直到sem中的资源数减为0时,资源被耗尽,线程被阻塞,当阻塞指定的时长之后,线程解除阻塞。// 调用该函数给sem中的资源数+1 int sem_post(sem_t *sem);
调用该函数会将
sem中的资源数+1,如果有线程在调用sem_wait、sem_trywait、sem_timedwait时因为sem中的资源数为0被阻塞了,这时这些线程会解除阻塞,获取到资源之后继续向下运行。// 查看信号量 sem 中的整形数的当前值, 这个值会被写入到sval指针对应的内存中 // sval是一个传出参数 int sem_getvalue(sem_t *sem, int *sval);
通过这个函数可以查看
sem中现在拥有的资源个数,通过第二个参数sval将数据传出,也就是说第二个参数的作用和返回值是一样的。6.2 生产者和消费者
由于生产者和消费者是两类线程,并且在还没有生成之前是不能进行消费的,在使用信号量处理这类问题的时候可以定义两个信号量,分别用于记录生产者和消费者线程拥有的总资源数。
// 生产者线程 sem_t psem; // 消费者线程 sem_t csem; // 信号量初始化 sem_init(&psem, 0, 5); // 5个生产者可以同时生产 sem_init(&csem, 0, 0); // 消费者线程没有资源, 因此不能消费 // 生产者线程 // 在生产之前, 从信号量中取出一个资源 sem_wait(&psem); // 生产者商品代码, 有商品了, 放到任务队列 ...... ...... ...... // 通知消费者消费,给消费者信号量添加资源,让消费者解除阻塞 sem_post(&csem); //////////////////////////////////////////////////////// //////////////////////////////////////////////////////// // 消费者线程 // 消费者需要等待生产, 默认启动之后应该阻塞 sem_wait(&csem); // 开始消费 ...... ...... ...... // 消费完成, 通过生产者生产,给生产者信号量添加资源 sem_post(&psem);
通过上面的代码可以知道,初始化信号量的时候没有消费者分配资源,消费者线程启动之后由于没有资源自然就被阻塞了,等生产者生产出产品之后,再给消费者分配资源,这样二者就可以配合着完成生产和消费流程了。
6.3 信号量使用
场景描述:使用信号量实现生产者和消费者模型,生产者有5个,往链表头部添加节点,消费者也有5个,删除链表头部的节点。
(1)总资源数为1
如果生产者和消费者线程使用的信号量对应的总资源数为1,那么不管线程有多少个,可以工作的线程只有一个,其余线程由于拿不到资源,都被迫阻塞了。
#include <stdio.h> #include <stdlib.h> #include <unistd.h> #include <string.h> #include <semaphore.h> #include <pthread.h> // 链表的节点 struct Node { int number; struct Node* next; }; // 生产者线程信号量 sem_t psem; // 消费者线程信号量 sem_t csem; // 互斥锁变量 pthread_mutex_t mutex; // 指向头结点的指针 struct Node * head = NULL; // 生产者的回调函数 void* producer(void* arg) { // 一直生产 while(1) { // 生产者拿一个信号灯 sem_wait(&psem); // 创建一个链表的新节点 struct Node* pnew = (struct Node*)malloc(sizeof(struct Node)); // 节点初始化 pnew->number = rand() % 1000; // 节点的连接, 添加到链表的头部, 新节点就新的头结点 pnew->next = head; // head指针前移 head = pnew; printf("+++producer, number = %d, tid = %ld\n", pnew->number, pthread_self()); // 通知消费者消费, 给消费者加信号灯 sem_post(&csem); // 生产慢一点 sleep(rand() % 3); } return NULL; } // 消费者的回调函数 void* consumer(void* arg) { while(1) { sem_wait(&csem); // 取出链表的头结点, 将其删除 struct Node* pnode = head; printf("--consumer: number: %d, tid = %ld\n", pnode->number, pthread_self()); head = pnode->next; free(pnode); // 通知生产者生成, 给生产者加信号灯 sem_post(&psem); sleep(rand() % 3); } return NULL; } int main() { // 初始化信号量 // 生产者和消费者拥有的信号灯的总和为1 sem_init(&psem, 0, 1); // 生成者线程一共有1个信号灯 sem_init(&csem, 0, 0); // 消费者线程一共有0个信号灯 // 创建5个生产者, 5个消费者 pthread_t ptid[5]; pthread_t ctid[5]; for(int i=0; i<5; ++i) { pthread_create(&ptid[i], NULL, producer, NULL); } for(int i=0; i<5; ++i) { pthread_create(&ctid[i], NULL, consumer, NULL); } // 释放资源 for(int i=0; i<5; ++i) { pthread_join(ptid[i], NULL); } for(int i=0; i<5; ++i) { pthread_join(ctid[i], NULL); } sem_destroy(&psem); sem_destroy(&csem); return 0; }
通过测试代码可以得到如下结论:如果生产者和消费者使用的信号量总资源数为1,那么不会出现生产者线程和消费者线程同时访问共享资源的情况,不管生产者和消费者线程有多少个,它们都是顺序执行的。
(2)总资源数大于1
如果生产者和消费者线程使用的信号量对应的总资源数为大于1,这种场景下出现的情况就比较多了:
- 多个生产者线程同时生产
- 多个消费者同时消费
- 生产者线程和消费者线程同时生产和消费
以上不管哪一种情况都可能会出现多个线程访问共享资源的情况,如果想防止共享资源出现数据混乱,那么就需要使用互斥锁进行线程同步,处理代码如下:
#include <stdio.h> #include <stdlib.h> #include <unistd.h> #include <string.h> #include <semaphore.h> #include <pthread.h> // 链表的节点 struct Node { int number; struct Node* next; }; // 生产者线程信号量 sem_t psem; // 消费者线程信号量 sem_t csem; // 互斥锁变量 pthread_mutex_t mutex; // 指向头结点的指针 struct Node * head = NULL; // 生产者的回调函数 void* producer(void* arg) { // 一直生产 while(1) { // 生产者拿一个信号灯 sem_wait(&psem); // 加锁, 这句代码放到 sem_wait()上边, 有可能会造成死锁 pthread_mutex_lock(&mutex); // 创建一个链表的新节点 struct Node* pnew = (struct Node*)malloc(sizeof(struct Node)); // 节点初始化 pnew->number = rand() % 1000; // 节点的连接, 添加到链表的头部, 新节点就新的头结点 pnew->next = head; // head指针前移 head = pnew; printf("+++producer, number = %d, tid = %ld\n", pnew->number, pthread_self()); pthread_mutex_unlock(&mutex); // 通知消费者消费 sem_post(&csem); // 生产慢一点 sleep(rand() % 3); } return NULL; } // 消费者的回调函数 void* consumer(void* arg) { while(1) { sem_wait(&csem); pthread_mutex_lock(&mutex); struct Node* pnode = head; printf("--consumer: number: %d, tid = %ld\n", pnode->number, pthread_self()); head = pnode->next; // 取出链表的头结点, 将其删除 free(pnode); pthread_mutex_unlock(&mutex); // 通知生产者生成, 给生产者加信号灯 sem_post(&psem); sleep(rand() % 3); } return NULL; } int main() { // 初始化信号量 sem_init(&psem, 0, 5); // 生成者线程一共有5个信号灯 sem_init(&csem, 0, 0); // 消费者线程一共有0个信号灯 // 初始化互斥锁 pthread_mutex_init(&mutex, NULL); // 创建5个生产者, 5个消费者 pthread_t ptid[5]; pthread_t ctid[5]; for(int i=0; i<5; ++i) { pthread_create(&ptid[i], NULL, producer, NULL); } for(int i=0; i<5; ++i) { pthread_create(&ctid[i], NULL, consumer, NULL); } // 释放资源 for(int i=0; i<5; ++i) { pthread_join(ptid[i], NULL); } for(int i=0; i<5; ++i) { pthread_join(ctid[i], NULL); } sem_destroy(&psem); sem_destroy(&csem); pthread_mutex_destroy(&mutex); return 0; }
在编写上述代码的时候还有一个需要注意是事项,不管是消费者线程的处理函数还是生产者线程的处理函数内部有这么两行代码:
// 消费者 sem_wait(&csem); pthread_mutex_lock(&mutex); // 生产者 sem_wait(&csem); pthread_mutex_lock(&mutex);
这两行代码的调用顺序是不能颠倒的,如果颠倒过来就有可能会造成死锁,下面来分析一种死锁的场景:
void* producer(void* arg) { // 一直生产 while(1) { pthread_mutex_lock(&mutex); // 生产者拿一个信号灯 sem_wait(&psem); ...... ...... // 通知消费者消费 sem_post(&csem); pthread_mutex_unlock(&mutex); // 生产慢一点 sleep(rand() % 3); } return NULL; } // 消费者的回调函数 void* consumer(void* arg) { while(1) { pthread_mutex_lock(&mutex); sem_wait(&csem); ...... ...... // 通知生产者生成, 给生产者加信号灯 sem_post(&psem); pthread_mutex_unlock(&mutex); sleep(rand() % 3); } return NULL; } int main() { // 初始化信号量 sem_init(&psem, 0, 5); // 生成者线程一共有5个信号灯 sem_init(&csem, 0, 0); // 消费者线程一共有0个信号灯 ...... ...... return 0; }
在上面的代码中,初始化状态下消费者线程没有任务信号量资源,假设某一个消费者线程先运行,调用
pthread_mutex_lock(&mutex);对互斥锁加锁成功,然后调用sem_wait(&csem);由于没有资源,因此被阻塞了。其余的消费者线程由于没有抢到互斥锁,因此被阻塞在互斥锁上。对应生产者线程第一步操作也是调用pthread_mutex_lock(&mutex);,但是这时候互斥锁已经被消费者线程锁上了,所有生产者都被阻塞,到此为止,多余的线程都被阻塞了,程序产生了死锁。