1.Introduction
1.1 问题引入
大规模的MDP问题如何估计价值函数?
答:在面对大规模MDP问题时,要避免用table去表示特征(Q-table等),而是采用参数的函数近似的方式去近似估计V、Q、
1.2 Solution
Estimate with function approximation
- Generalize from seen states to unseen states
- Update the parameter w using MC and TD learning
1.3 Types of value function approximation
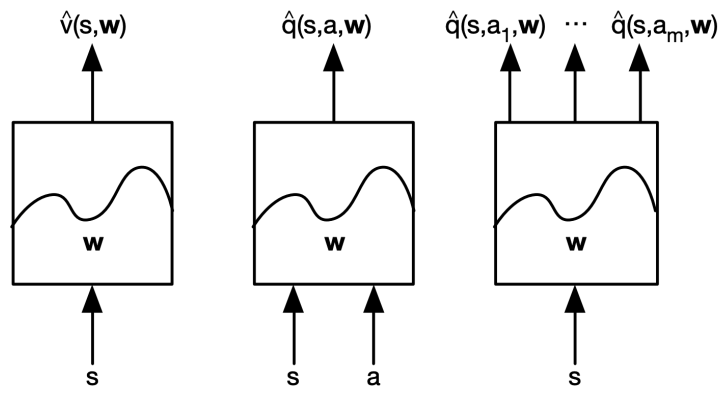
1.4 近似方法
- Linear combinations of features
- Neural networks
- Decision trees
- Nearest neighbors
1.5 梯度下降
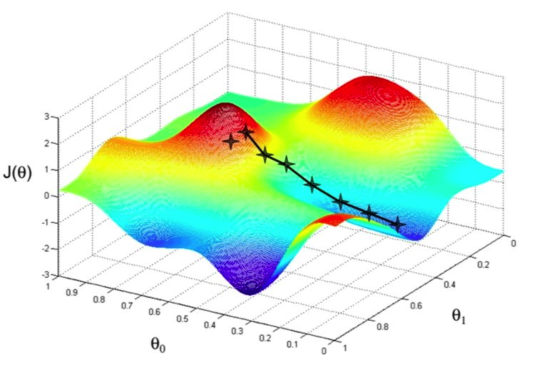
- Consider a function that is a differentiable function of a parameter vector
- Goal is to find parameter that minimizes
- Define the gradient of to be
- Adjust in the direction of the negative gradient, where is step-size
1.6 Value Function Approximation with an Oracle
Oracle是Ground Truth/真值的意思,想要拟合最准确的v函数,就可以用已知policy下v函数的值拟合v函数
- We assume that we have the oracle for knowing the true value for for any given state
- Then the objective is to find the best approximate representation for
- Thus use the mean squared error and define the loss function as
- Follow the gradient descend to find a local minimum
2.Prediction
2.1 已知Oracle
Represent state using a feature vector :
(1) 已知V Function是线性
随机梯度下降收敛到全局最优。 因为在线性情况下,只有一个最优解,因此局部最优解为自动收敛到或接近全局最优。
- Represent value function by a linear combination of features
- The objective function is quadratic in parameter
- Thus the update rule is as simple as
- Stochastic gradient descent converges to global optimum. Because in the linear case, there is only one optimum, thus local optimum is automatically converge to or near the global optimum.
(2)Table Lookup Feature
如果用one-hot编码,Table Lookup Feature
- Table lookup is a special case of linear value function approximation
- Table lookup feature is one-hot vector as follows
- Then we can see that each element on the parameter vector indicates the value of each individual state
- Thus we have
拟合出的价值函数就是等于
2.2 未知Oracle
(1)Model-free Prediction with VFA
基于采样计算
In practice, no access to oracle of the true value for any state
Recall model-free prediction
- Goal is to evaluate following a fixed policy
- A lookup table is maintained to store estimates or
- Estimates are updated after each episode (MC method) or after each step (TD method)
Thus what we can do is to include the function approximation step in the loop
Incremental VFA Prediction Algorithms
- We assumed that true value function given by supervisor / oracle
- But in RL there is no supervisor, only rewards
- In practice, we substitute the target for
- For MC, the target is the actual return
- For TD(0), the target is the TD target
- For MC, the target is the actual return
(2)Monte-Carlo Prediction with VFA
MC return的Gt特点:无偏估计、但是有很大噪声(采很多次样才能得出结果),方差大
Return G_t is an unbiased, but noisy sample of true value v^{\pi}(s_t)
Why unbiased?
so we have the training data that can be used for supervised learning in VFA:
Using linear Monte-Carlo policy evaluation
Monte-Carlo prediction converges, in both linear and non-linear value function approximation
(3)TD Prediction with VFA
TD target特点:有偏估计(取期望时包含了正在优化的W)
TD target is a biased sample of true value
Why biased? It is drawn from our previous estimate, rather than the true value:
We have the training data used for supervised learning in VFA:
Using linear TD(0), the stochastic gradient descend update is
This is also called as semi-gradient, as we ignore the effect of changing the weight vector w on the target
Linear TD(0) converges(close) to global optimum
3.Control
Generalized policy iteration
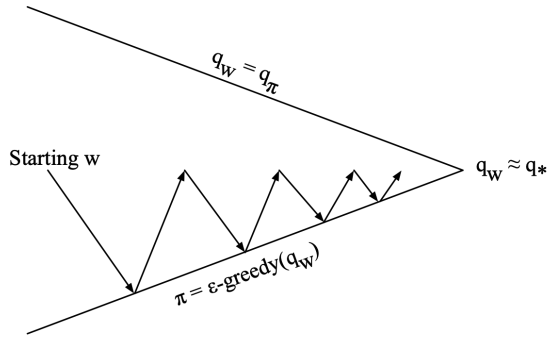
Policy evaluation: approximate policy evaluation,
Policy improvement: policy improvement
3.1 Q函数(Action-value Function)估计
(1)已知实际Q函数
可通过计算MSE和梯度下降的方法估计Q函数:
Approximate the action-value function
Minimize the MSE (mean-square error) between approximate action-value and true action-value (assume oracle)
Stochastic gradient descend to find a local minimum
(2)如果Q函数为线性
Represent state and action using a feature vector
Represent action-value function by a linear combination of features
Thus the stochastic gradient descend update
3.2 Value function approximation
如果没有获得真正的Ground truth的Q函数,用Gt或TD target代替oracle, 从而更新Q函数近似函数的参数。
For MC, the target is return
For Sarsa, the target is TD target
For Q-learning, the target is TD target
其中,Sarsa for VFA Control :

3.3 VFA Control的收敛问题
TD在使用off-policy或使用非线性函数拟合时会发散(难以收敛)
TD with VFA 得出来目标函数的梯度是不准确的(gradient本身包含了正在优化的参数)
update包含了Bellman backup的近似和价值函数的近似
off-policy的behavior policy(采取数据的策略) and target policy(优化的策略)不完全相同,因此价值估计函数难以收敛
3.4 强化学习的死亡三角
强化学习不确定不稳定的因素
- Function approximation:近似V或者Q会引入误差
- Bootstrapping:TD基于之前来估计当前函数会引入噪声,使得网络过拟合;MC用了实际的return,而且是无偏的,所以稍微好些(如果足够多会近似真值)
- Off-policy training:采用behavior policy来采取数据,但优化的是target policy,导致采集的数据和优化的函数是不一样的
3.5 控制算法的收敛性问题
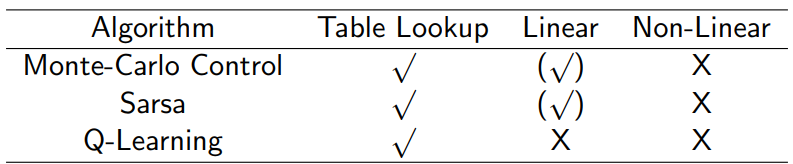
(√) moves around the near-optimal value function
3.6 Batch优化
之前单步优化效率低,Batch-based方法优化batch中所有样本,
3.7 Least Square Prediction
目标:求D数据库中pair的最小均方差
Given the value function approximation
The experience consisting of pairs (may from one episode or many previous episodes)
Objective: To optimize the parameter that best fit all the experience
Least squares algorithms are used to minimize the sum-squared error between and the target values
如果数据集太大,每次随机采样部分样本,计算梯度并优化函数,不断迭代。
4.Deep Q Networks
4.1 Deep Reinforcement Learning
Frontier in machine leaning and artificial intelligence
Deep neural networks are used to represent
- value function
- Policy function (policy gradient methods to be introduced)
- World model
Loss function is optimized by stochastic gradient descent(SGD)
Challenges
- Efficiency : too many model parameters to optimize
- The Deadly Triad for the danger of instability and divergence in training
- Nonlinear function approximation
- Bootstrapping
- Off-policy training
4.2 DQN for Playing Atari Games
End-to-end learning of values Q(s,a) from input pixel frame
Input state is a stack of raw pixels from latest 4 frames
Output of is 18 joystick / button positions
Reward is the change in score for that step
Network architecture and hyperparameters fixed across all games
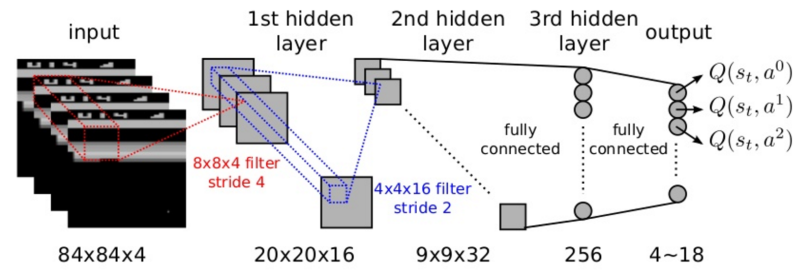
4.3 训练DQN问题及解决方法
- 样本之间的具有相关性:Experience replay
- 不稳定的目标:Fixed Q targets
4.4 DQNs: Experience Replay
To reduce the correlations among samples, store transition (s_t, a_t, r_t, s_{t+1}) in replay memory D
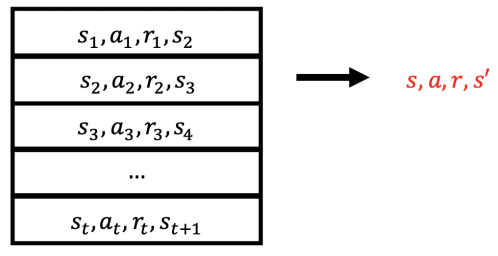
To perform experience replay, repeat the following
- sample an experience tuple from the dataset:
- compute the target value for the sampled tuple:
- use stochastic gradient descent to update the network weights
4.5 DQNs: Fixed Targets
To help improve stability, fix the target weights used in the target calculation for multiple updates
Let a different set of parameter be the set of weights used in the target, and be the weights that are being updated
To perform experience replay with fixed target, repeat the following
- sample an experience tuple from the dataset:
- compute the target value for the sampled tuple:
- use stochastic gradient descent to update the network weights
4.6 Loss
在计算loss时,我们是通过计算TD target(Q_target)和当前Q value(Q的估计)的差来得到的。

但是其实对于真实的TD target,我们是不知道的,没有概念的。我们也是需要预测的。使用Bellman 方程,我们发现TD target仅仅是当前动作的reward加上通过衰减的下一个state的最高Q value。

问题是我们使用同样的参数(网络权重)来估计target和Q value。这就使得网络权重和TD target具有很强的相关性。 因此,这就意味着训练的每一步,我们的Q value偏移了,同时Q target也偏移了。
所以我们将使用一个单独的固定参数的网络(w-)来预测TD target
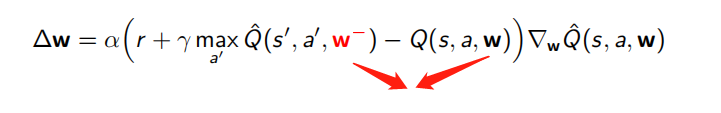
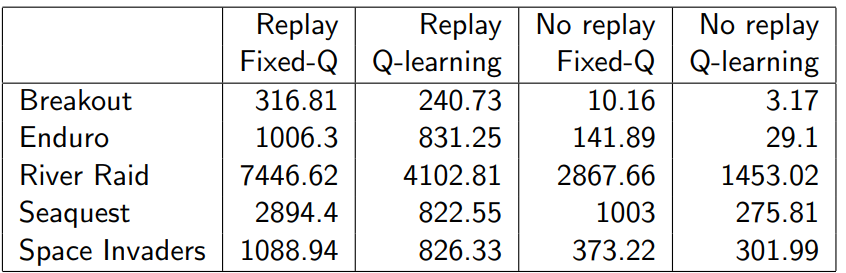
4.7结果和Demo
- Demo of Breakout by DQN : https://www.youtube.com/watch?v=V1eYniJ0Rnk
- Demo of Flappy Bird by DQN : https://www.youtube.com/watch?v=xM62SpKAZHU
- Code of DQN in PyTorch : https://github.com/cuhkrlcourse/DeepRL-Tutorials/blob/master/01.DQN.ipynb
- Code of Flappy Bird : https://github.com/xmfbit/DQN-FlappyBird
- 参考:https://blog.csdn.net/mike11222