1、基本概念
- 二叉查找树是为了实现快速查找而生的
- 左子树结点值 < 根结点值 < 右子树节点值
- 默认不允许两个结点的关键字相同
2、查找操作
- 先取根结点,如果它等于要查找的数据,那就返回;
- 如果要查找的数据比根结点的值小,那就在左子树中递归查找;
- 如果要查找的数据比根结点的值大,那就在右子树中递归查找
2.1 查找成功ASL
查找成功的前提:只需考虑查找树中已有的结点即可。
方法:将所有查找成功的情况都列举出来,然后比较次数求和再取平均。
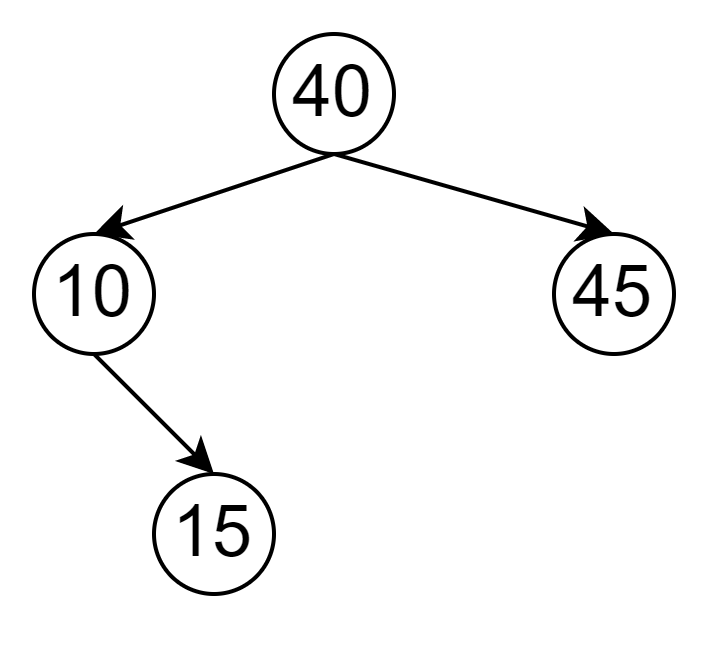
- 找40:比较一次
- 找45:比较两次
- 找10:比较两次
- 找15:比较三次
所以:
ASLsucc = (1+2+2+3)/4 = 22.2 查找失败ASL
找到空子树,还没找到结点,那么结点一定不存在
空结点算不算一次比较?比较是跟结点比较,但是空指针域是属于最后一个比较节点上的,所以空结点不算一次比较
- 第一种 40→ 10 → 左空子树,2次
- 第二种 40 → 10 → 15 → 左空子树,3次
- 第三种 40 → 10 → 15 → 右空子树,3次
- 第四种 40 → 45 → 左空子树,2次
- 第五种 40 → 45 → 右空子树,2次
所以:
ASLfail = (2+3+3+2+2)/5 = 12/52.4 递归查找
// 递归搜索,空间复杂度为O(h) BSTNode* searchRecBST(BSTree T, ElemType key) { if (key == T->data) return T; if (key < T->data) T = searchRecBST(T->lchild, key); else T = searchRecBST(T->rchild, key); return T; }
2.5 非递归查找
// 非递归查找,空间复杂度为O(1) BSTNode* searchBST(BSTree T, ElemType key) { // 若树空或等于根结点,则循环结束 while (T != NULL && key != T->data) { if (key < T->data) T = T->lchild; else T = T->rchild; } return T; }
3、插入操作
- 新插入的数据一般都是在叶子结点
- 只需要从根结点开始,依次比较要插入的数据和结点的大小关系;
- 如果要插入的数据比结点的数据大,并且结点的右子树为空,就将新数据插入到右节点的位置,如果不为空,就再递归遍历右子树,查找插入位置;
- 同理,插入左子树
// 插入数据 bool insertBST(BSTree& T, ElemType key) { if (T == NULL) { BSTNode* pNode = (BSTNode*)malloc(sizeof(BSTNode)); pNode->lchild = NULL; pNode->rchild = NULL; pNode->data = key; T = pNode; return true; } else if (key == T->data) return false; else if (key < T->data) return insertBST(T->lchild, key); else return insertBST(T->rchild, key); }
4、创建二叉排序树
// 指向二叉排序树根结点的指针T为空 // 不断往这颗T指向的二叉排序树中插入结点 BSTree createBST(ElemType keyList[], int keyListLength) { if (keyListLength <= 0) return NULL; BSTree T = NULL; for (int i = 0; i < keyListLength; i++) { insertBST(T, keyList[i]); } return T; }
5、删除操作
主要思想:针对删除结点的子树个数不同,将删除结点存在两个子树,转化为存在一个子树的方式删除。
5.1 方法一
- 如果删除的结点没有子节点,直接将父节点中指向该结点的指针置为NULL;
- 如果删除的结点只有一个结点,只需要将父结点中,指向删除结点的指针,指向要删除结点的子结点即可;
- 如果删除的结点有两个子结点,需要找到这个结点的右子树中的最小结点,把它替换到要删除的结点上,然后再删除这个最小结点,因为最小结点肯定没有左子节点,用上面两条规则删除。
5.2 方法二
- 如果删除的结点没有子节点,直接将父节点中指向该结点的指针置为NULL;
- 如果删除的结点只有一个结点,只需要将父结点中,指向删除结点的指针,指向要删除结点的子结点即可;
- 如果删除的结点有两个子结点,找到删除结点的左子树中的最大者,将右子树的根结点挂到左子树中最大者的右孩子上,之后使用删除一个结点的方法删除。
代码实现主要分两步:
5.2.1 删除值的查找
使用递归方法找到要删除的结点
// 删除递归操作 void deleteNodeBST(BSTree& T, ElemType x) { if (T == NULL) return; if (x == T->data) { deleteOper(T); } else if (x < T->data) deleteNodeBST(T->lchild, x); else deleteNodeBST(T->rchild, x); }
5.2.2 删除这个结点
删除结点分四种情况:
- 只有一个结点:直接删除
- 右孩子存在,左孩子不存在:删除结点,将指针指向右孩子
- 左孩子存在,右孩子不存在:删除结点,将指针指向左孩子
- 左右孩子都存在:找到删除结点左子树中的最大值结点(右侧寻找),将删除结点的右子树挂在左子树的最大节点的右孩子上。
// 结点删除操作 void deleteOper(BSTree& T) { // 1、只有这一个结点,直接置为空 if (T->lchild == NULL && T->rchild == NULL) { free(T); T = NULL; } // 2、右孩子存在,左孩子不存在 else if (T->lchild == NULL) { BSTNode* pNode = T; T = T->rchild; free(pNode); } // 3、左孩子存在,右孩子不存在 else if (T->rchild == NULL) { BSTNode* pNode = T; T = T->lchild; free(pNode); } // 4、左右孩子都存在 else { // 寻找左子树的最大值 BSTNode* pLeftMax = T->lchild; while (pLeftMax->rchild != NULL) { pLeftMax = pLeftMax->rchild; } // 将右子树挂在左子树的最大值 pLeftMax->rchild = T->rchild; // 释放删除结点的内存 BSTNode* pNode = T; T = T->lchild; free(pNode); } }
6、Sample
6.1 将树分成两颗
问题
将一棵二叉排序树t分解成两棵二叉排序树t1与t2,使得t1中的所有结点关键字的值都小于key,t2中所有关键字的值都大于key。
算法思想
- 如果key等于根结点(子树根节点),那么将左子树和右子树分别插入到T1和T中;
- 如果key大于根结点,那么将根和左子树插入T1中,然后继续分解右子树;
- 如果key小于根结点,那么将根和右子树插入T2中,继续对左子树进行划分;
- 重复上述步骤,直到树中不存在为划分结点;
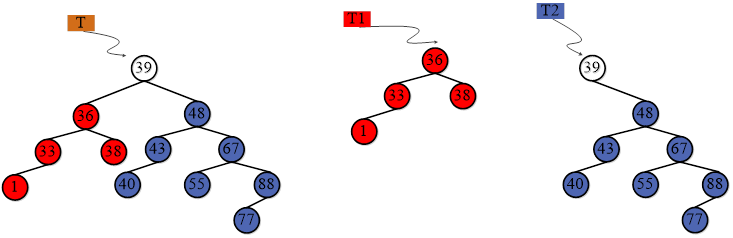
删除结点(分解)一般使用先序遍历。左子树和右子树的情况进行下一部分的操作,必须结点。
代码
// 将一个结点插入排序树中 void insertNodeBSTree(BSTree& T, BSTNode* rNode) { if (T == NULL) T = rNode; else if (rNode->data < T->data) insertNodeBSTree(T->lchild, rNode); else insertNodeBSTree(T->rchild, rNode); }
// 先序遍历划分树 void preOrderTraversing(BSTree T, ElemType key, BSTree& T1, BSTree& T2) { if (T == NULL) return; // 1、key小于根,说明右子树和根都大于key, // 将右子树和根插入T2,左子树继续分解 if (key < T->data) { preOrderTraversing(T->lchild, key, T1, T2); T->lchild = NULL; // 注意:左子树分完了,不存在了 insertNodeBSTree(T2, T); } // 2、key等于根,左子树插入T1,右子树插入T2 else if (key == T->data) { insertNodeBSTree(T1, T->lchild); insertNodeBSTree(T2, T->rchild); free(T); T = NULL; } // 3、key大于根,说明左子树和根都小于key, // 将左子树和根插入T1,右子树继续分解 else { preOrderTraversing(T->rchild, key, T1, T2); T->rchild = NULL; insertNodeBSTree(T1, T); } }
void spiltBST(BSTree T, ElemType key, BSTree& T1, BSTree& T2) { T1 = NULL; T2 = NULL; preOrderTraversing(T, key, T1, T2); }
6.2 删除小于x的结点
问题
已知二叉排序树中每一个结点值为整型,采用二叉链表存储编写算法,删除二叉排序树中所有结点值小于x的结点。
分析
最关键要知道根结点,然后左右子树的取值范围!然后根据这个范围,要不要对子树进行递归操作。先序遍历,先知道根结点才能知道左右子树的范围。
算法思想
- 使用先序遍历搜索小于x的结点并将其删除。
- 如果当前访问结点大于x,那么使用先序遍历搜索并删除其左子树中小于x的结点,保留该节点与其右子树;
- 如果当前结点小于x,那么先序遍历搜索并删除其右子树中小于x的结点后,再直接删除左子树中所有结点;
- 如果当前访问结点等于x,那么直接删除该结点及其左子树,保留右子树。
代码
// 删除一颗二叉树 void deleteTree(BSTree& T) { if (T == NULL) return; deleteTree(T->lchild); deleteTree(T->rchild); T->lchild = NULL; T->rchild = NULL; free(T); T = NULL; }
// 先序遍历删除小于x的结点 void preOrderDeleteLessNode(BSTree &T, ElemType x) { if (T == NULL) return; // 等于根结点,删除左子树 if (T->data == x) { // 删除左孩子,指控左指针 deleteTree(T->lchild); T->lchild = NULL; } // 根结点小于x,删除左子树,右子树可能存在小于x的数 else if (T->data < x) { // 右子树递归删除小于x的结点 preOrderDeleteLessNode(T->rchild, x); // 删除左子树 deleteTree(T->lchild); T->lchild = NULL; // 删除根结点 BSTNode* pNode = T; T = T->rchild; free(pNode); pNode = NULL; } // 根结点大于x,左子树可能存在小于x的数,右子树全部大于x else if (T->data > x) { // 左子树递归删除小于x的结点 preOrderDeleteLessNode(T->lchild, x); } }
6.3 查找二叉排序树中小于key的关键字
问题
查找二叉排序树中小于key的关键字
算法思想
方法一:在中序遍历输出哪儿判断是否要输出
方法二:中序遍历的时候,如果访问的结点大于等于key,后面的结点都不再访问。
如果说只要打印小于key的结点,那么中序遍历时访问根结点,根结点大于等于key,右子树一定时大于key,那么右子树的中序遍历将不再执行。
- 中序遍历左、中、右,将获得升序序列
- 中序遍历右、中、左,将获得降序序列
注意
可用于:topK,最大的几个,最小的几个,大于x值得结点 ...
// 查找二叉排序树中小于key的关键字 void inOrderPrintLessNode(BSTree T, ElemType x) { if (T == NULL) return; inOrderPrintLessNode(T->lchild, x); if (T->data >= x) // 这个地方判断打印的结点小于key ? 是的, 就打印 return; printf("%d ", T->data); //这个函数执行的时候,一定打印大于key的关键字 inOrderPrintLessNode(T->rchild, x); }
6.4 寻找比value大的最小值
问题
存在一个二叉排序树,给定一个value值,若查找value值,就返回比value值大的所有值中最小的值。若value最大就返回空。
分析
找一批值,中序序列获得大于Value的值,从中选取最小的值;使用变量保存上一次打印的值。
算法思想
- 使用中序序列获得降序序列;
- 先访问右子树,再访问(打印)根结点,如果根结点小于等于key,那么上一次打印的结点即为比key大的结点中的最小值;
- 反之,继续遍历左子树,直到遇见小于等于key的结点或结点访问完时停止搜索。
利用中序遍历序列获得一个序列,利用根结点的判断,截取这个序列中的一部分序列。
代码
// 寻找比value大的最小值 // preNode :保存上一次访问的结点 void inOrderCloserValue(BSTree T, ElemType value, BSTNode*& preNode) { if (T == NULL) return; inOrderCloserValue(T->rchild, value, preNode); if (T->data > value) { preNode = T; // 保存当前结点,然后从左子树中查找大于value的结点 // /如果有可能存在大于value的结点在左子树中,所以递归调用进行查找 inOrderCloserValue(T->lchild, value, preNode); } }