加载tokenizer对象:
In [ ]:
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("bert-base-cased")
d:\Software\Miniconda3\envs\llm\lib\site-packages\tqdm\auto.py:21: TqdmWarning: IProgress not found. Please update jupyter and ipywidgets. See https://ipywidgets.readthedocs.io/en/stable/user_install.html from .autonotebook import tqdm as notebook_tqdm tokenizer_config.json: 100%|██████████| 29.0/29.0 [00:00<?, ?B/s] d:\Software\Miniconda3\envs\llm\lib\site-packages\huggingface_hub\file_download.py:147: UserWarning: `huggingface_hub` cache-system uses symlinks by default to efficiently store duplicated files but your machine does not support them in C:\Users\dd\.cache\huggingface\hub. Caching files will still work but in a degraded version that might require more space on your disk. This warning can be disabled by setting the `HF_HUB_DISABLE_SYMLINKS_WARNING` environment variable. For more details, see https://huggingface.co/docs/huggingface_hub/how-to-cache#limitations. To support symlinks on Windows, you either need to activate Developer Mode or to run Python as an administrator. In order to see activate developer mode, see this article: https://docs.microsoft.com/en-us/windows/apps/get-started/enable-your-device-for-development warnings.warn(message) config.json: 100%|██████████| 570/570 [00:00<00:00, 571kB/s] vocab.txt: 100%|██████████| 213k/213k [00:00<00:00, 479kB/s] tokenizer.json: 100%|██████████| 436k/436k [00:00<00:00, 1.40MB/s]
使用tokenizer对一条文本进行编码:
In [ ]:
encoded_input = tokenizer("Do not meddle in the affairs of wizards, for they are subtle and quick to anger.")
print(encoded_input)
{'input_ids': [101, 2091, 1136, 1143, 13002, 1107, 1103, 5707, 1104, 16678, 1116, 117, 1111, 1152, 1132, 11515, 1105, 3613, 1106, 4470, 119, 102], 'token_type_ids': [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0], 'attention_mask': [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]}
使用 tokenizer 对编码结果进行解码,从下述输出结果中可以看出,在编码时不仅仅是将文本转为了 id,同时还在头尾分别添加了 [CLS] 和 [SEP] 这两个字符:
In [ ]:
tokenizer.decode(encoded_input["input_ids"])
Out[ ]:
'[CLS] Do not meddle in the affairs of wizards, for they are subtle and quick to anger. [SEP]'
除了每次处理单条数据,还可以一次处理一批数据,代码结果如下:
In [ ]:
batch_sentences = [
"But what about second breakfast?",
"Don't think he knows about second breakfast, Pip.",
"What about elevensies?",
]
encoded_inputs = tokenizer(batch_sentences)
print(encoded_inputs)
{'input_ids': [[101, 1252, 1184, 1164, 1248, 6462, 136, 102], [101, 1790, 112, 189, 1341, 1119, 3520, 1164, 1248, 6462, 117, 21902, 1643, 119, 102], [101, 1327, 1164, 5450, 23434, 136, 102]], 'token_type_ids': [[0, 0, 0, 0, 0, 0, 0, 0], [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0], [0, 0, 0, 0, 0, 0, 0]], 'attention_mask': [[1, 1, 1, 1, 1, 1, 1, 1], [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1], [1, 1, 1, 1, 1, 1, 1]]}
接下来的功能分别是 padding、截断、返回指定框架的类型的tensor,对应的输入参数为:padding、truncation、return_tensors,代码结果如下:
In [ ]:
batch_sentences = [
"But what about second breakfast?",
"Don't think he knows about second breakfast, Pip.",
"What about elevensies?",
]
encoded_input = tokenizer(batch_sentences, padding=True, truncation=True, return_tensors="pt")
print(encoded_input)
{'input_ids': tensor([[ 101, 1252, 1184, 1164, 1248, 6462, 136, 102, 0, 0,
0, 0, 0, 0, 0],
[ 101, 1790, 112, 189, 1341, 1119, 3520, 1164, 1248, 6462,
117, 21902, 1643, 119, 102],
[ 101, 1327, 1164, 5450, 23434, 136, 102, 0, 0, 0,
0, 0, 0, 0, 0]]), 'token_type_ids': tensor([[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]]), 'attention_mask': tensor([[1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0],
[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1],
[1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0]])}
另外,在使用 tokenizer 时可传的参数还有:max_length、return_attention_mask、`return_token_type_ids`` 等等,可以具体用到时再了解。
查看tokenizer中所有的vocab,可以调用get_vocab()函数获取,返回值是一个字典,该字典的key是token,value是该token对应的id,而函数get_vocab()对应的实现也很简单,如下述几行代码:
In [ ]:
def get_vocab(self):
vocab = {self.convert_ids_to_tokens(i): i for i in range(self.vocab_size)}
vocab.update(self.added_tokens_encoder)
return vocab
2.从头训练一个tokenizer¶
参考资料:
下面以 BPE 为例,看一下如何从头训练一个 tokenizer。
首先实例化一个 tokenizers.models 对象,然后创建一个 Tokenizer:
In [ ]:
from tokenizers import Tokenizer
from tokenizers.models import BPE
model = BPE(unk_token="[UNL]")
tokenizer = Tokenizer(model)
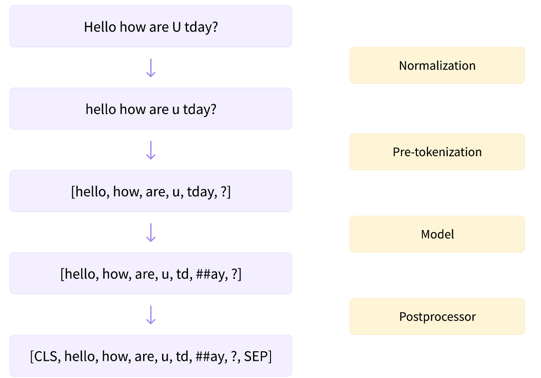
有了 tokenizer 对象之后,接下来是为其配置 pipeline 中各个部分,整个 pipeline 有如下几部分:
- normalization
- pre-tokenization
- model
- post-processing
关于这个pipeline的详情会在下一个小章节详细介绍。在这里,作为例子,仅设置 pre-tokenization 部分,其他部分采用默认值。设置 pre-tokenization 部分的代码如下:
In [ ]:
from tokenizers.pre_tokenizers import Whitespace
tokenizer.pre_tokenizer = Whitespace()
如果要训练的话还需要一个 trainer 对象,初始化代码如下。该对象创建时还可以传入 vocab_size、min_frequency 等参数,这些具体使用时可以看相应的API。对 special_tokens 传入的参数要特别说明一下,这里传入的 special token 的顺序就是生成的 vocab 中的顺序,比如如下代码的话,最终 "[UNK]" 对应id为0,"[CLS]" 对应id为1,"[SEP]" 对应id为2,"[PAD]" 对应id为3,"[MASK]" 对应id为4。
In [ ]:
from tokenizers.trainers import BpeTrainer
trainer = BpeTrainer(special_tokens=["[UNK]", "[CLS]", "[SEP]", "[PAD]", "[MASK]"])
上述步骤完成之后,就可以通过给定的语料进行训练了,代码如下:
In [ ]:
files = [f"dataset/tokenizers/wikitext-2/wiki.{split}.tokens" for split in ["test", "train", "valid"]]
tokenizer.train(files, trainer)
训练完成之后要进行保存,代码如下:
In [ ]:
tokenizer.save("dataset/tokenizers/tokenizer-wiki.json")
至此,整个训练过程就全部完成了,如果要使用自己刚才保存的文件加载 tokenizer 对象,代码如下:
In [ ]:
tokenizer = Tokenizer.from_file("dataset/tokenizers/tokenizer-wiki.json")
在使用 tokenizer.encode() 时,其内部总共是经历了如下四个步骤:
- normalization
- pre-tokenization
- model
- post-processing
下面分别介绍一下每个步骤所起的功能,并给出部分代码样例。
3.1 normalization¶
该步骤是标准化步骤,包括一些常规清理,例如删除不必要的空格、大写转小写、以及删除重音符号。
对于别人已经训练好的 tokenizer,如果想要访问其 normalizer 可以采用如下代码的形式。在下述代码中,由于采用的是大小写无关的 bert 模型,所以其 tokenizer 会把所有的大写都转为小写。
In [ ]:
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("bert-base-uncased")
normalizer = tokenizer.backend_tokenizer.normalizer
print("I love China")
print(normalizer.normalize_str("I love China"))
I love China i love china
另外,还可以自己从 tokenizers.normalizers 中 import 各种 normalizer 操作,样例代码如下:
In [ ]:
import tokenizers
normalizer = tokenizers.normalizers.Lowercase()
print("I love China")
print(normalizer.normalize_str("I love China"))
I love China i love china
3.2 pre-tokenization¶
对于别人已经训练好的 tokenizer,如果想要访问其 pre_tokenizer 可以采用如下代码的形式。在下述代码中,采用的是 gpt2-xl 的 tokenizer,它是使用 Byte-Level BPE,并且会把空格替换为一个特殊的字符 Ġ,然后可以看到其还会跟踪每个单词的偏移。
In [ ]:
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("gpt2-xl")
pre_tokenizer = tokenizer.backend_tokenizer.pre_tokenizer
print("I love China")
print(pre_tokenizer.pre_tokenize_str("I love China"))
config.json: 100%|██████████| 689/689 [00:00<00:00, 690kB/s] vocab.json: 100%|██████████| 1.04M/1.04M [00:01<00:00, 969kB/s] merges.txt: 100%|██████████| 456k/456k [00:00<00:00, 1.92MB/s] tokenizer.json: 100%|██████████| 1.36M/1.36M [00:00<00:00, 1.73MB/s]
I love China
[('I', (0, 1)), ('Ġlove', (1, 6)), ('ĠChina', (6, 12))]
另外,pre_tokenizer 也是可以自己创建的,其路径为 tokenizers.pre_tokenizers,下面的样例代码是自己创建一个 ByteLevel 的 pre_tokenizer:
In [ ]:
import tokenizers
pre_tokenizer = tokenizers.pre_tokenizers.ByteLevel()
print("I love China")
print(pre_tokenizer.pre_tokenize_str("I love China"))
I love China
[('ĠI', (0, 1)), ('Ġlove', (1, 6)), ('ĠChina', (6, 12))]
3.3 model¶
输入的文本经过 normalizer 和 pre_tokenizer 之后,接下来就会对文本执行 tokenize 操作,该步骤就是执行 tokenize 操作的。
model 有如下几种:
- tokenizers.models.BPE
- tokenizers.models.Unigram
- tokenizers.models.WordLevel
- tokenizers.models.WordPiece
经过该步骤之后,就得到了 token 序列。
3.4 post-processing¶
这个步骤所做的操作包括:
- 按照配置在 token 序列中添加各种
special token; - 生成 attention mask 和 token type ids;
- 如果是 NSP 任务,或者相似度任务,还会把两条数据拼接到一块;
这部分的样例代码可参考:https://huggingface.co/docs/tokenizers/pipeline#postprocessing
In [ ]:
Comment